少即是多!78条数据完胜1万条? 高质量数据才是AI真壁垒|上交大/SII最新
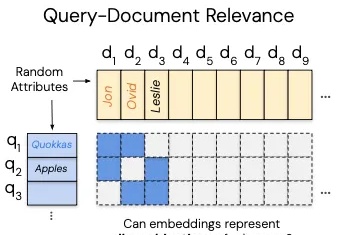
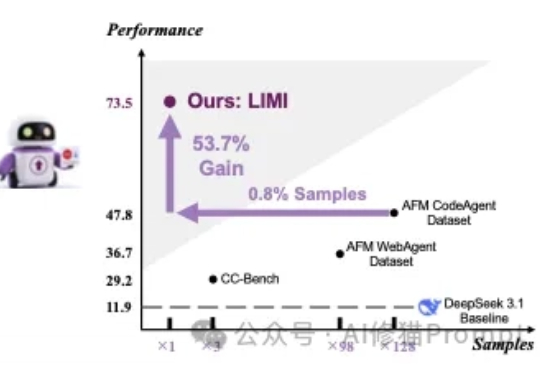
少即是多!78条数据完胜1万条? 高质量数据才是AI真壁垒|上交大/SII最新对于提升AI能主动发现问题、提出假设、调用工具并执行解决方案,在真实环境里闭环工作,而不只是在对话里“想”的智能体能力(Agency)。在这篇论文之前的传统方法认为,需要遵循传统语言模型的“规模法则”(Scaling Laws)才能实现,即投入更多的数据就能获得更好的性能。
来自主题: AI技术研报
8777 点击 2025-09-25 15:21